记录一次Sqoop从MySQL导入数据到Hive问题的排查经过
问题描述
MySQL中原始数据有790W+的记录数,在Sqoop抽取作业成功的情况下在Hive中只有500W左右的记录数。
排查过程
数据导入脚本Log
通过Log可以发现以下信息:
- 该Sqoop任务被分解为4个MapTask。
- MapTask执行期间有异常,是网络异常导致MySQL连接不成功。
- Sqoop任务对应的MR执行过程中总的被调起9个MapTask,其中3个失败、2个被kill,理论上剩余的4个MapTask是成功执行的。
- Sqoop导入对应的MR只有MapTask,且MapTask的数据记录数为790W+。所以,单纯看MR的输出是正常的。
- Sqoop导入完成后,紧跟着有一个读取Sqoop目标表数据的
insert overwrite的操作。该操作只被分解为2个MapTask,说明原数据文件只有两个块。 - 根据以上信息说明Sqoop之后确实只生成了2个数据文件,有两个文件丢失了。
详细原始Log信息见附件:Sqoop执行日志
查看Sqoop任务对应MR的执行日志
根据上面的Log中的信息,从HDFS上查找对应的日志。Yarn所有的应用执行日志在HDFS的/data/hadoop/yarn-logs/hadoop/logs/目录下。从该目录下查找应用程序application_1533196506314_4460157 的日志。日志会包含MR在各个节点上执行的信息。
从Log中发现以下异常信息:
1 | 2018-12-10 00:42:30,595 FATAL [IPC Server handler 17 on 8046] org.apache.hadoop.mapred.TaskAttemptListenerImpl: Task: attempt_1533196506314_4460157_m_000001_0 - exited : org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.LeaseExpiredException): No lease on /user/hive/warehouse/ods.db/bss_customer_fj/_SCRATCH0.3130352759450352/dt=20181209/_temporary/1/_temporary/attempt_1533196506314_4460157_m_000001_0/part-m-00001 (inode 761544109): File does not exist. Holder DFSClient_attempt_1533196506314_4460157_m_000001_0_-1729942809_1 does not have any open files. |
所以,怀疑是MR在执行结束时,将临时文件移动到正式目录时发生错误。
原始Log文件见目录:
- 192-168-72-12_27463
- 192-168-72-24_16310
- 192-168-72-84_13498
- 192-168-72-93_53778
- 192-168-72-23_18284
- 192-168-72-73_2363
- 192-168-72-88_24481
- 192-168-72-94_54353
查看DN Log信息
根据上面的Log信息,发现DN节点192-168-72-24上的MapTask有以下异常信息。
192-168-72-24异常信息:
1 | 2018-12-10 00:42:34,410 WARN [main] org.apache.hadoop.mapred.YarnChild: Exception running child : org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.server.namenode.LeaseExpiredException): No lease on /user/hive/warehouse/ods.db/bss_customer_fj/_SCRATCH0.3130352759450352/dt=20181209/_temporary/1/_temporary/attempt_1533196506314_4460157_m_000000_0/part-m-00000 (inode 761544157): File does not exist. Holder DFSClient_attempt_1533196506314_4460157_m_000000_0_798513081_1 does not have any open files. |
所以怀疑是MapTask的最后阶段写文件的时候未成功。检查该DN节点的Log发现以下异常信息:
1 | 2018-12-10 00:42:32,643 ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: BlockSender.sendChunks() exception: |
百度之后发现该异常信息跟DN的一个配置有关系,具体配置项是DN可以同时处理的文件上限。对于老版本配置项名称为“dfs.datanode.max.xcievers”,对于新版本配置项名称改为“dfs.datanode.max.transfer.threads”。该参数的默认值为4096,所以需要修改为8192。
查看NN Log信息
默认的,Log4j输出的NameNode日志文件只保留最近的20个文件。因为NN的Log信息比较多,20个文件保存的日志不足1天,异常时间的日志已经被冲掉了。
查看NN信息
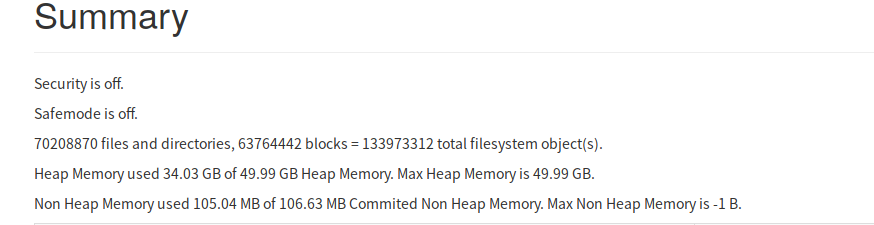
通过NN WebUI查看发现NN内存的使用已经70%左右,负载已经比较高。
处理措施
综合以上信息,其实问题发生的根本原因未能查明。基于对Hadoop了解的深度、精力及对故障恢复的容忍程度的考虑,待定位根本原因再解决问题的方案不可控。所以,采取以下改进措施:
(1)修改DN最大处理文件数量上限至8192。
(2)将NN内存扩展到100G。
(3)修改Sqoop源代码,当落地到目标HDFS目录下的文件数量与MapTask数量不一致时返回错误状态,并由调度系统进行重新抽取。