Hive/Spark SQL数字格式化
如果数字长度过大,则会以科学技术法的方式展现。通过一下例子可以复现,如下:
1 | create table t1 (d decimal(18,8)) stored as orc; |
如果需要按照原始数值展示,则可以用使用format_number函数,如下:
如果数字长度过大,则会以科学技术法的方式展现。通过一下例子可以复现,如下:
1 | create table t1 (d decimal(18,8)) stored as orc; |
如果需要按照原始数值展示,则可以用使用format_number函数,如下:
错误信息如下:
1 | 2022-08-28 00:29:37.447 ERROR 123200 --- [ main] o.s.boot.SpringApplication : Application startup failed |
这是由于 JDK 8 中有关反射相关的功能自从 JDK 9 开始就被限制了,两种方法解决:
1 | sudo apt remove cmdtest |
使用 gpasswd,如下:
1 | sudo gpasswd -d test docker |
将test用户从docker用户组中删除。其他用法参见gpasswd手册。
命令添加以下选项:
1 | docker ps --no-trunc |
Spark的宽依赖与窄依赖是跟数据分区关联的概念。
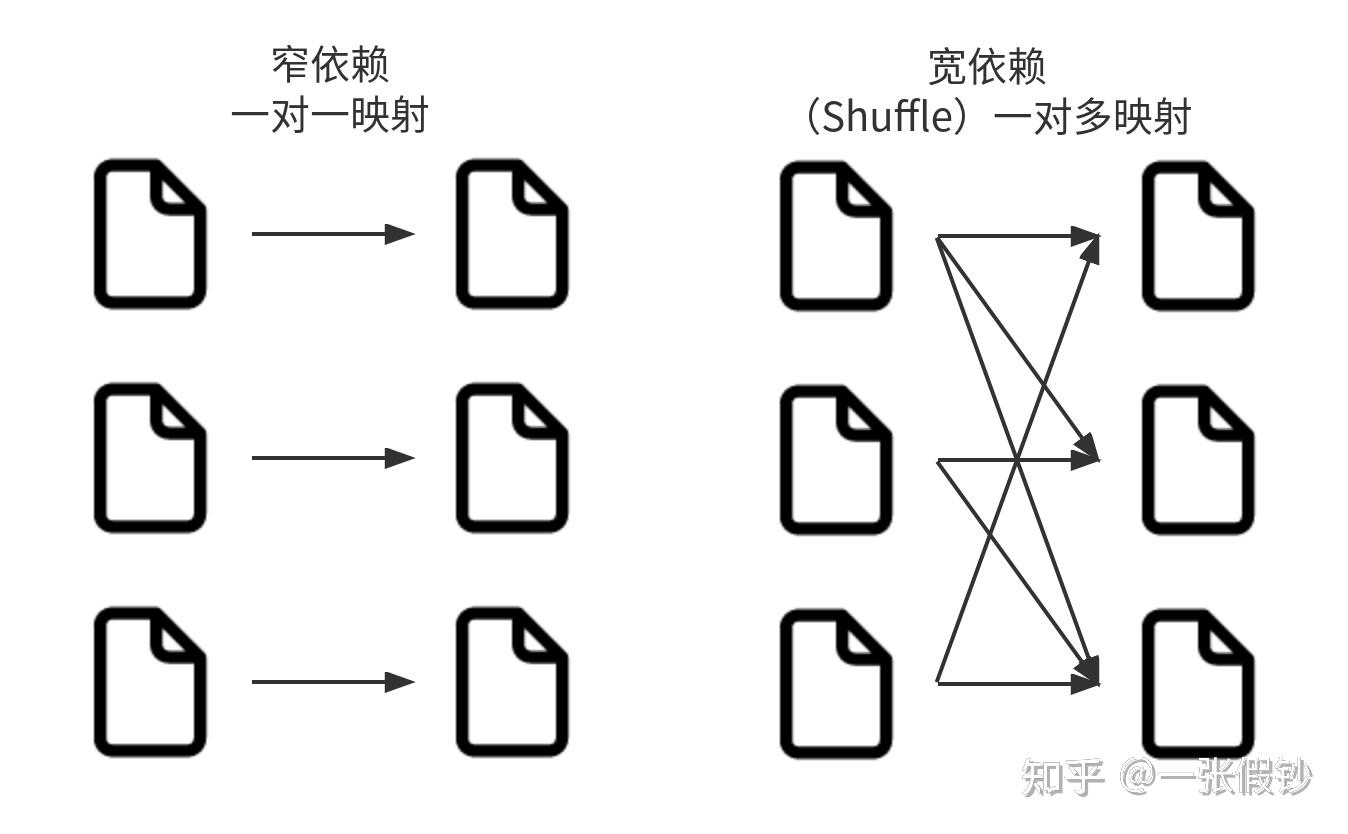
针对宽依赖的优化是讨论比较多的话题。这也引出了惰性评估的主题。惰性评估的意思就是等到绝对需要时才执行计算。惰性评估的好处是Spark可以优化整个从输入到输出端的数据流。一个很好的例子就是Dataframe的谓词下推。
Spark架构非常简洁。简洁的架构是良好开放性、兼容性的基础。