Linux下^M处理
此处针对shell脚本运行时报^M引起的异常,但是通过vi查看未显示^M的情况下如何处理。针对这种情况可以使用sed命令进行替换,如下:
1 | sed -i 's/^M//g' file1.txt |
注意:^M其实是CTRL+V与CTRL+M的组合。
此处针对shell脚本运行时报^M引起的异常,但是通过vi查看未显示^M的情况下如何处理。针对这种情况可以使用sed命令进行替换,如下:
1 | sed -i 's/^M//g' file1.txt |
注意:^M其实是CTRL+V与CTRL+M的组合。
1 | SELECT FROM test.test_hbase_table LIMIT 100; |
解决方法是在hbase-site.xml文件中添加如下配置:
此文是在现在容器实例上修改端口映射,并不希望创建新的容器,这样可以保持原有容器中的数据。
方法是修改容器目录下 hostconfig.json 配置文件中的 PortBindings 配置项内容。如下:
1 | "PortBindings":{"8080/tcp":[{"HostIp":"","HostPort":"8080"}]} |
异常信息:
1 | Unhandled exception: 'gbk' codec can't decode byte 0xa2 in position 43; illegal multibyte sequence |
如图: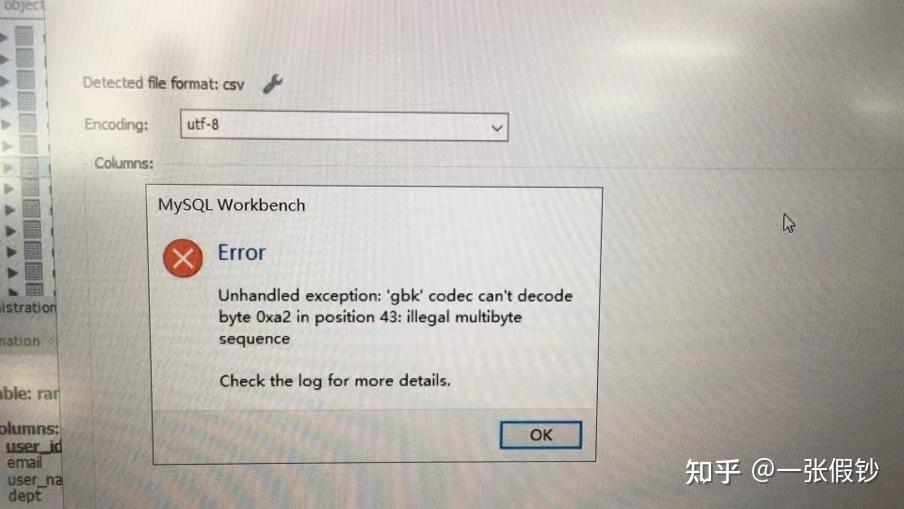
命令样例:
1 | $ ls |
以上命令是在末尾追加“ abc”。关键就是sed工具的使用,详细的可以查看sed使用手册。
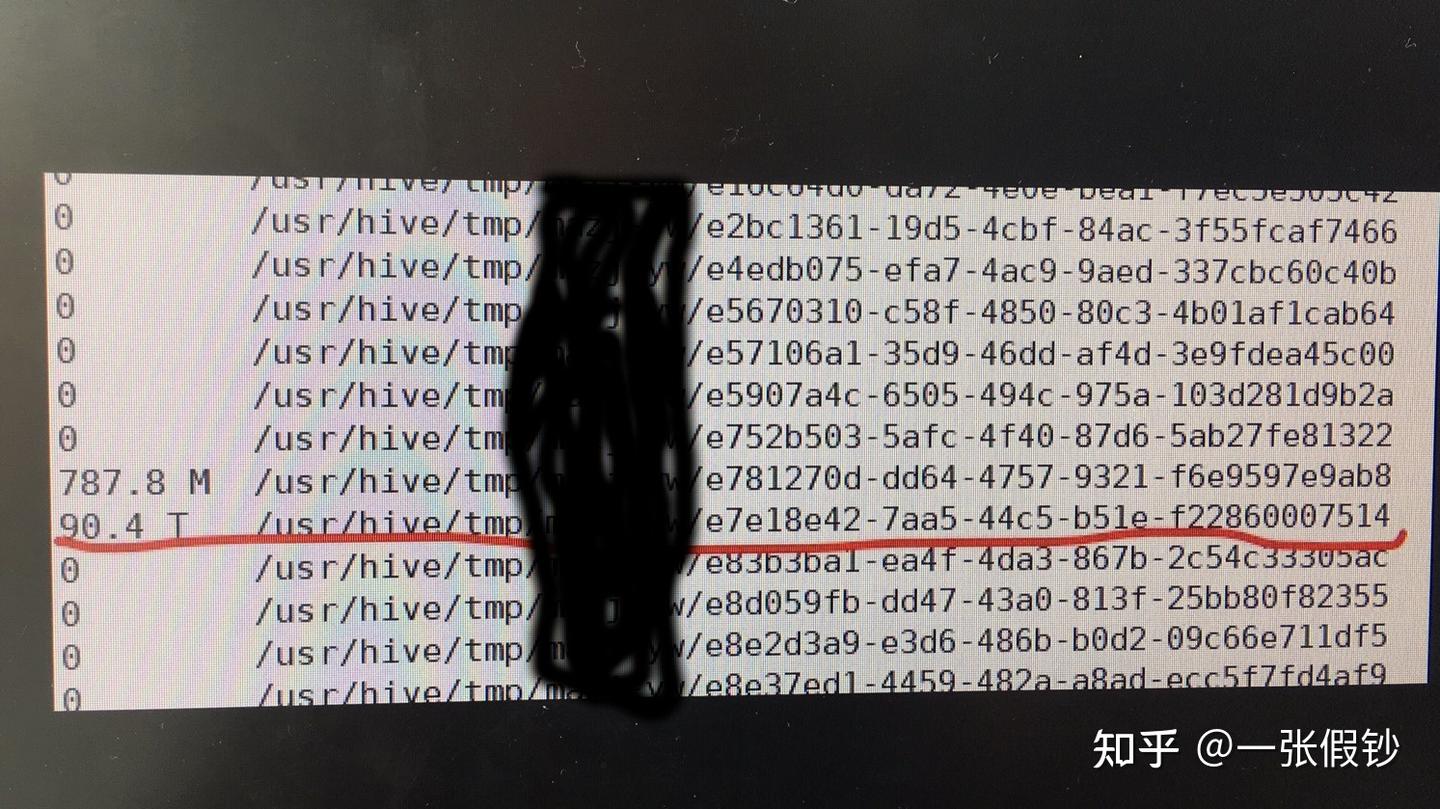
最近两天发现Hadoop集群中的Datanode存储严重不均衡,有一台DN存储增长非常快,远远超出了其他节点。即使启动了Balance进城也无法解决问题。
经过排查发现是因一个异常任务停留在reduce阶段,在不停的向HDFS写数据。而这个Reduce Task就是在存储增长非常快的节点上运行的。分析原因是Reduce Task会优先向运行在的节点本地写数据,副本会分布在其他节点上。所以,问题节点增长非常快,而其他节点并看不出明显异常。
以下是排查过程的图片:



使用 uptime 命令可以方便检查服务器是否发生了重启。uptime 命令手册中说:uptime会在一行中显示下列信息:当前时间、系统运行了多久时间、当前登录的用户有多少,以及前 1、5 和 15 分钟系统的平均负载。当然可以添加参数以不同的方式展示信息,如下:
1 | $ uptime |
记录一个加速镜像网站“liquidtelecom”,以TCL
下载为例,原下载地址如下:
1 | https://jaist.dl.sourceforge.net/project/tcl/Tcl/8.6.11/tcl8.6.11-src.tar.gz |
1 | docker run --name Redis -it centos bash |
今天在执行 hexo deploy 部署时,出现以下异常:
1 | remote: error: GH013: Repository rule violations found for refs/heads/master. |
其中的关键提示信息是: