MongoDB 常用查询
- 当前 MongoDB 版本:
db.version(); - Web控制台
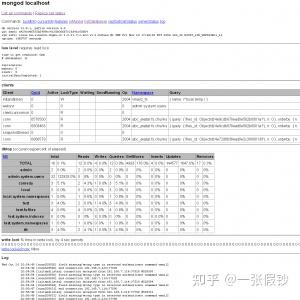
Mongodb 自带了 Web 控制台,默认和数据服务一同开启。他的端口在 Mongodb 数据库服务器端口的基础上加 1000 ,如果是默认的Mongodb数据服务端口 27017 ,则相应的Web端口为 28017。这个页面可以看到:- 当前Mongodb的所有连接。
- 各个数据库和Collection的访问统计,包括:Reads, Writes, Queries, GetMores ,Inserts, Updates, Removes。
- 写锁的状态。
- 以及日志文件的最后几百行。
参考截图: