Socket.IO 聊天应用实例
本篇翻译自 http://Socket.IO 官网的入门实例:http://socket.io/get-started/chat/。
在本篇指导中,我们将创建一个基本的聊天应用。这个应用几乎不要求事先具有 Node.JS 或 http://Socket.IO 的基础知识,因此对任意知识水平的用户它都是适合的。
引言
Mac OS 常用快捷键
- 显示桌面:command + F3
- 剪切、粘贴:先 command + C,再 command + option + V
- 终端 Shell 新建标签:command + T
- 屏幕快照:command + shift + 3
- 区域截屏:command + shift + 4
Socket.IO Java 客户端
Socket.IO 是一个非常棒的项目;Java 是目前应用非常广的开发语言。两者的结合也是必然的。本篇翻译自 Socket.IO-client Java 项目的 github 主页。
Socket.IO-client Java 是 Socket.IO v1.x 的 Java 客户端类库,这个类库是从 JavaScript client 移植过来的。
参见:
在 Linux 平台上安装 64 位 JDK
这个过程使用二进制打包文件(.tar.gz)为 64 位 Linux 安装 Java 开发包(JDK)。
本教程使用文件:jdk-8uversion-linux-x64.tar.gz
- 下载文件
Windows下Jenkins服务未自动重启问题解决
成功安装 Jenkins 服务后,有时开机后 Jenkins 服务未自动启动。查看 Jenkins 服务安装目录下的日志发现没有服务启动的日志,所以猜测是系统启动后 Jenkins 服务未调起。
通过按 Win + R,然后输入 services.msc 并按回车来打开服务管理工具。找到 Jenkins 服务,点击右键,查看“属性”,Jenkins 默认设置如下: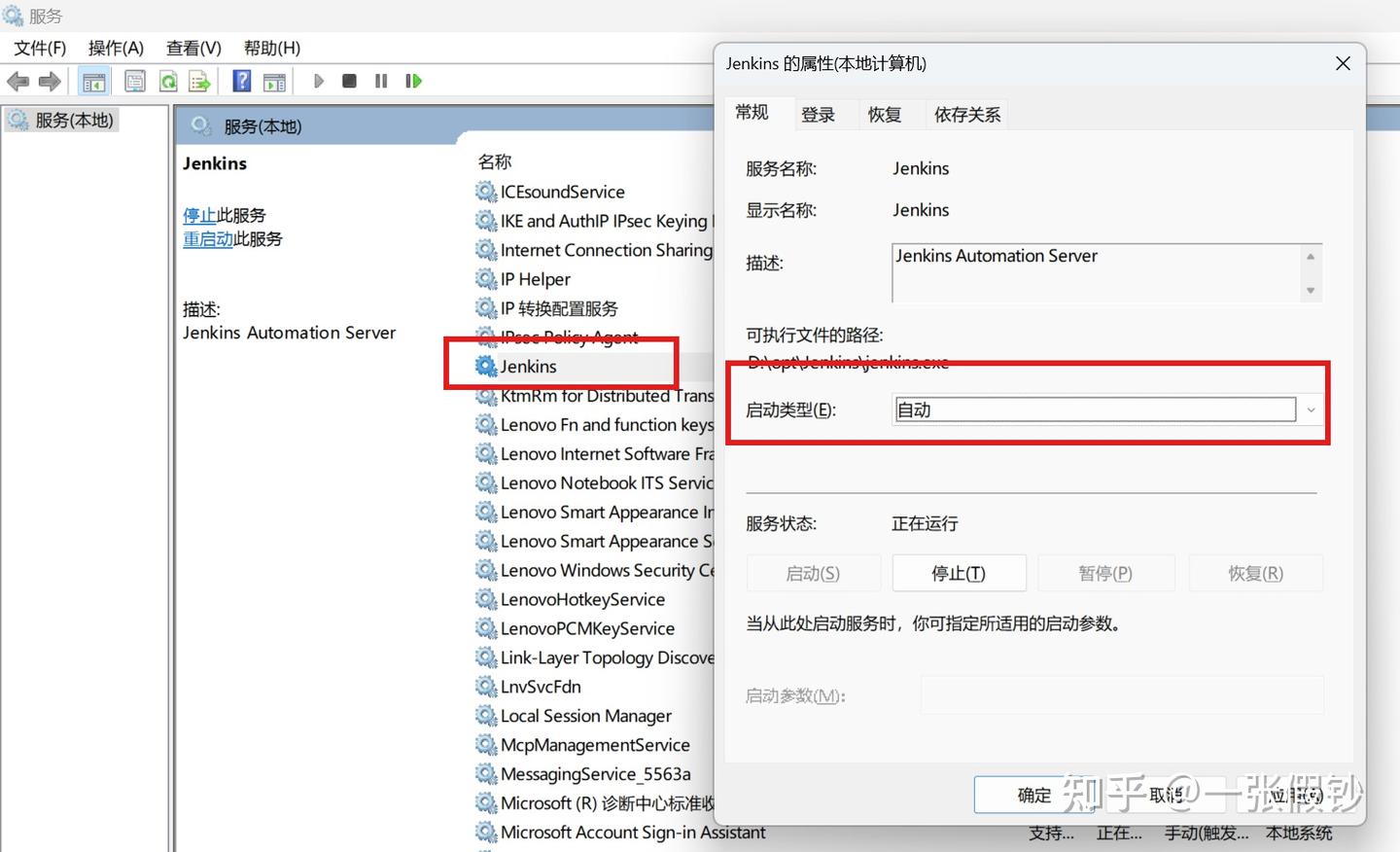
为了每次开机能自动启动 Jenkins 服务,更改配置如下: