Hadoop Eclipse 插件
环境
- Mac OS X EI Capitan 10.11.6
- java version “1.7.0_80”
- Hadoop 2.7.3:安装路径 /Users/ling/frin/work/hadoop/hadoop-2.7.3
- Eclipse Mars.2 Release (4.5.2):安装路径 /Users/ling/frin/apps/Eclipse.app/Contents/Eclipse。
安装 Hadoop
按照官方文档 Hadoop: Setting up a Single Node Cluster. 安装并配置伪分布式模式,并启动 hdfs。
插件安装
Hadoop Eclipse 插件项目 Github 地址:https://github.com/winghc/hadoop2x-eclipse-plugin。项目的 release 目录下有已经编译好的 jar 包,此处使用 hadoop-eclipse-plugin-2.6.0.jar。
下载 hadoop-eclipse-plugin-2.6.0.jar,然后将下载的 jar 包放到 ${ECLIPSE_HOME}/plugins 目录下,重启 Eclipse 安装完毕。
配置插件
Map/Reduce Locations 配置
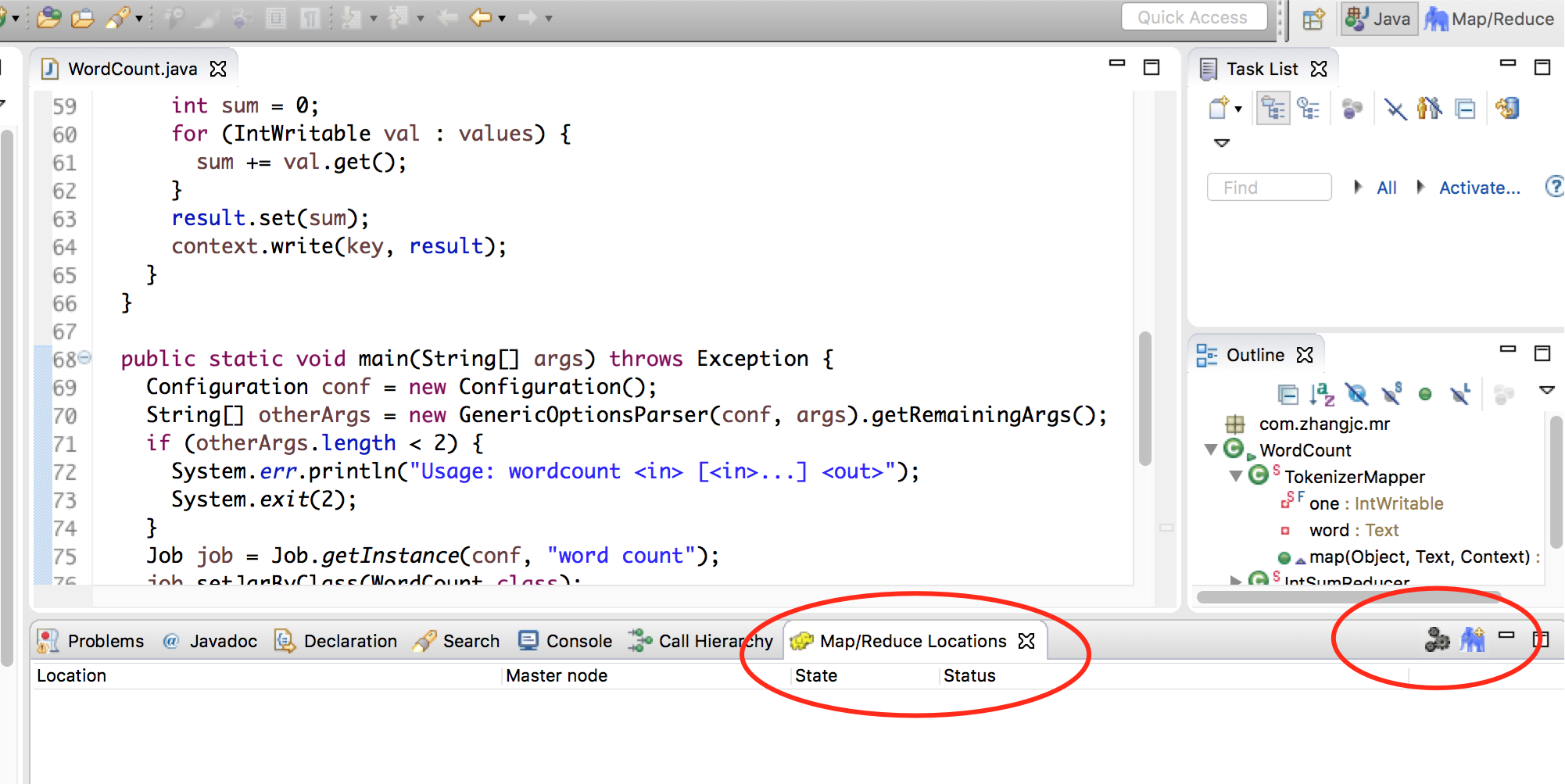
- 在菜单栏中选中 Window -> Show View -> Other…,在对话框中选中 MapReduce Tools -> Map/Reduce Locations,在 Eclipse 中会展示 Map/Reduce Locations 视图,如下图:
- 在 Map/Reduce Locations 视图中点击右上方小象图标会弹出参数配置窗口,如下图:
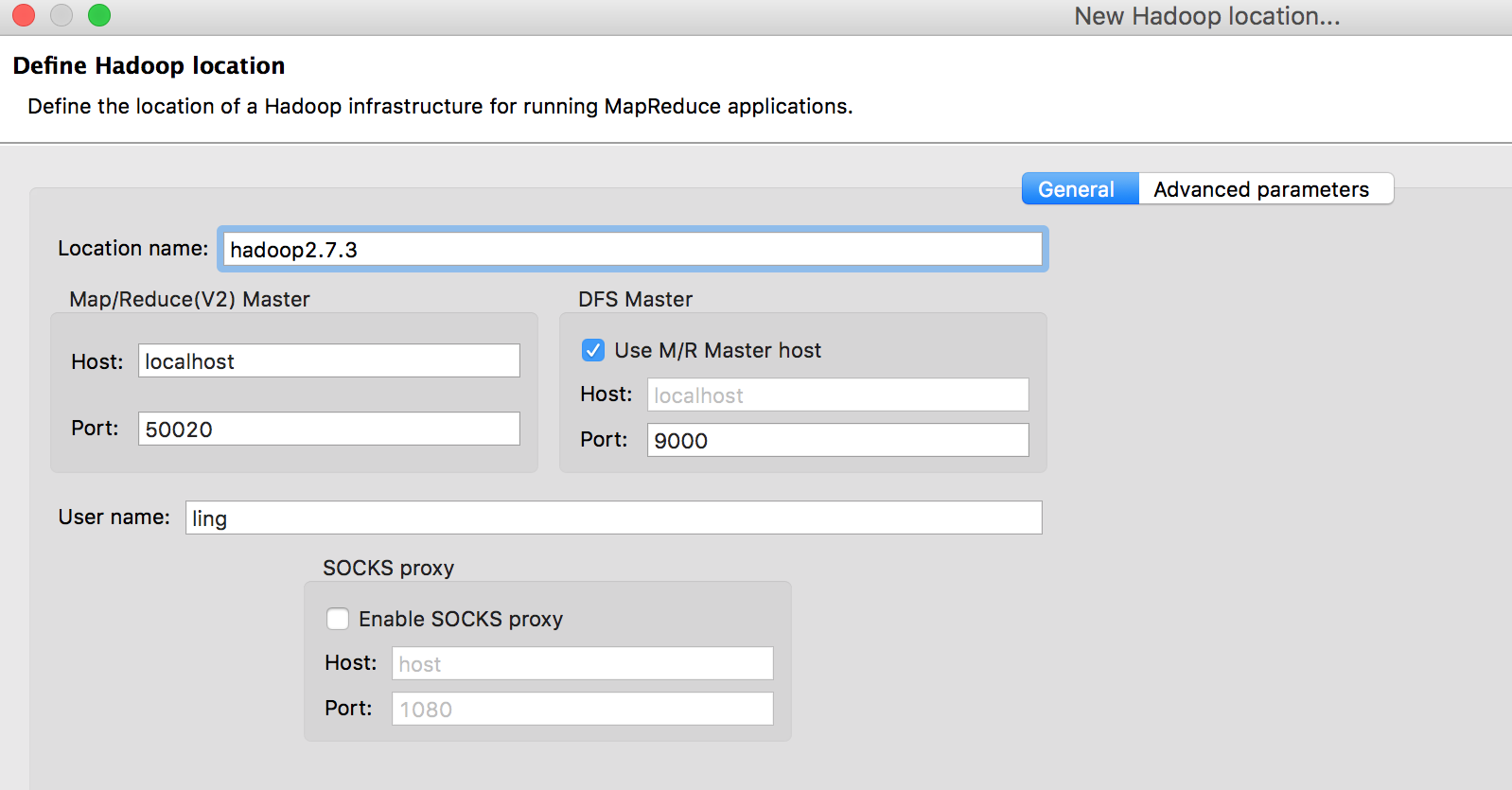
参数配置介绍:
- Location name:自定义名称
- Map/Reduce(V2) Master:
- Host:Map/Reduce 运行的 Host,此处为 localhost
- Port:该参数在新版本 Hadoop 中不需要,所以保持默认
- DFS Master:
- 选中“Use M/R Master host“选项
- Host:上面的选项选中后,该参数默认
- Port:需要跟 Hadoop 配置文件 ${HADOOP_HOME}/etc/hadoop/core-site.xml 中 fs.defaultFS 参数中配置的端口一致。
- User name:运行 Hadoop 的系统用户名
Hadoop 安装目录配置
在菜单栏中选中 Eclipse -> 偏好设置。在弹出的窗口中选中“Hadoop Map/Reduce“,在右侧设置 Hadoop 安装目录,如下图: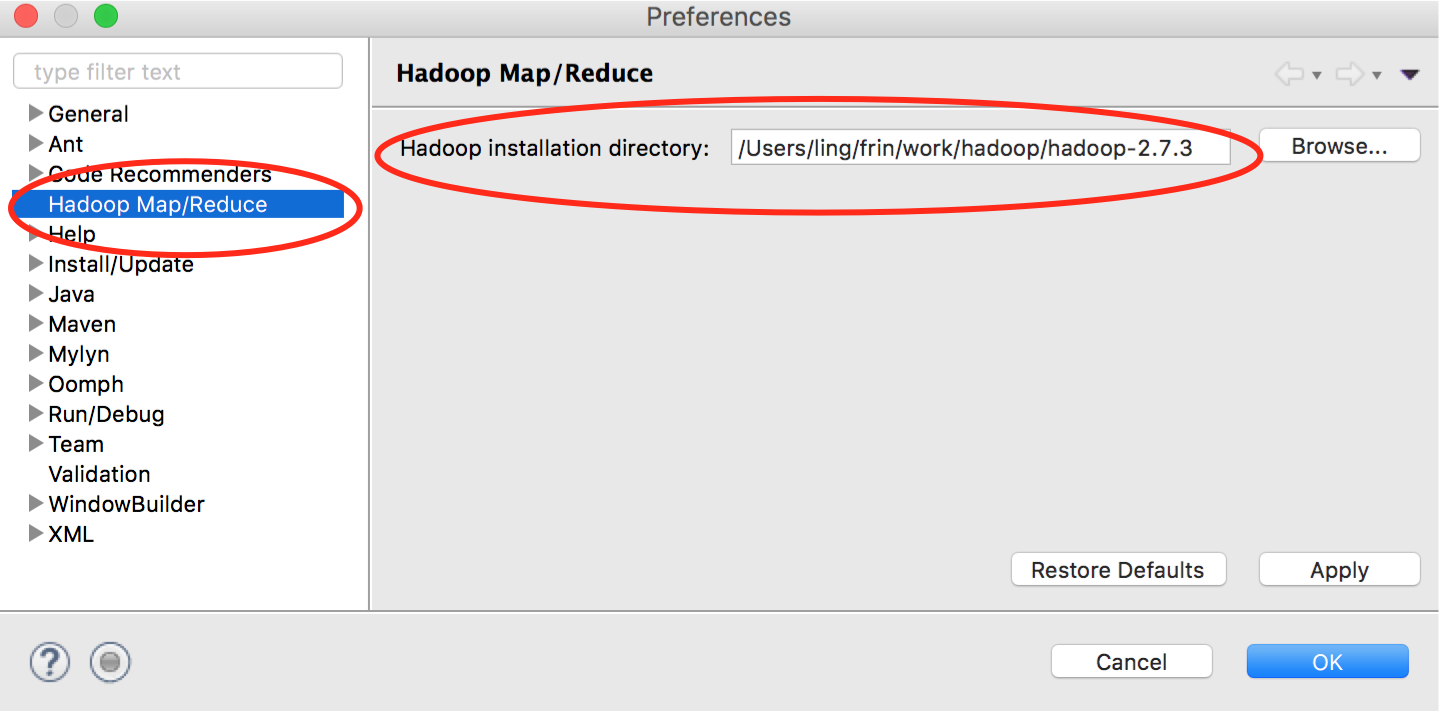
验证
配置完成后点击 finish 按钮完成配置。此时在 Map/Reduce Location View 中会显示刚配置的 Location name;在 Project Explore 视图中会显示 DFS Locations,下面也会有刚配置的 Location nam,如下图: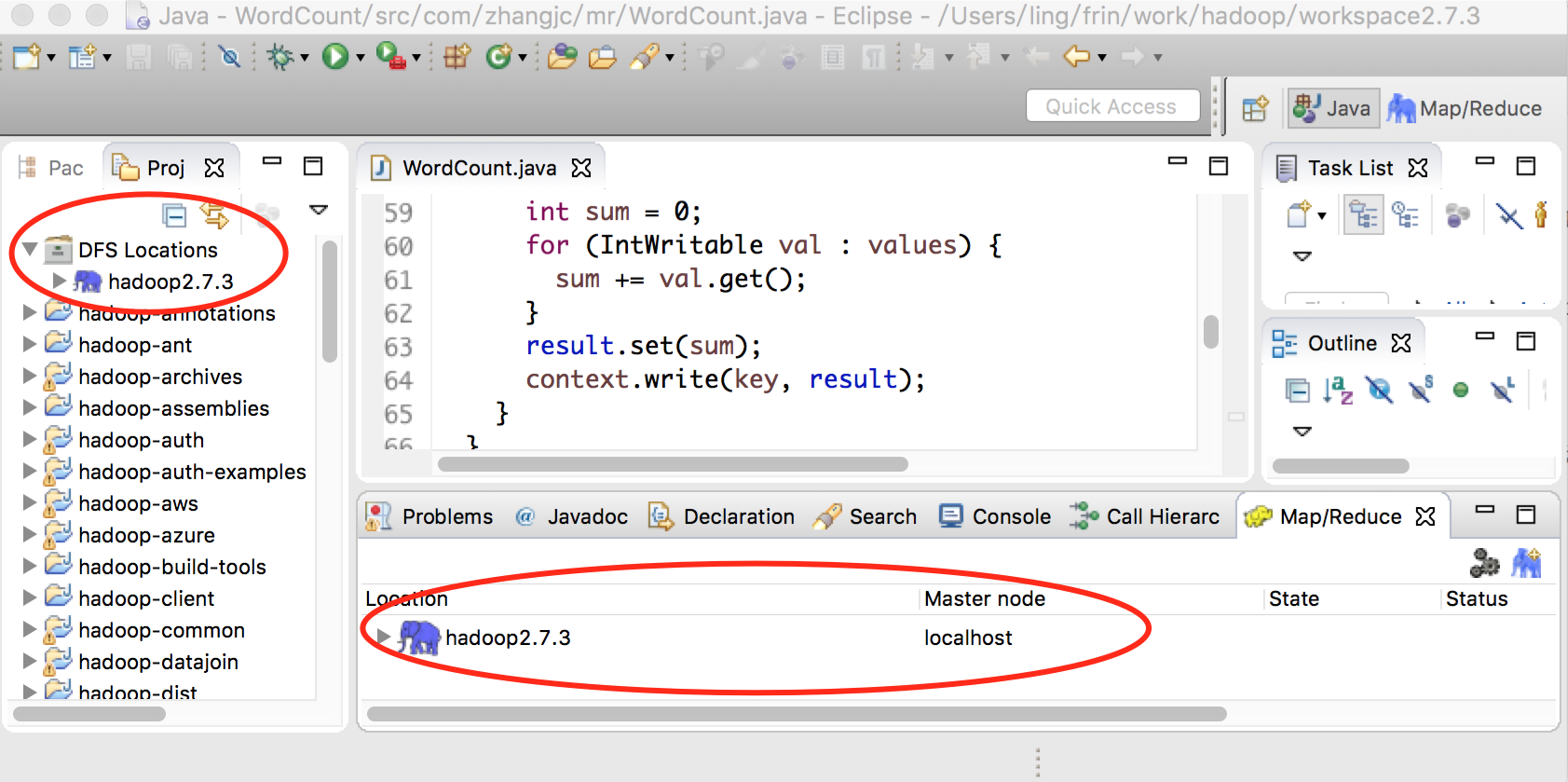
通过 DFS Location 可以管理 HDFS 目录。
运行 MapReduce 作业
新建 MapReduce 工程
在菜单栏中选择 File -> New -> Other -> MapReduce Project,然后点击 Next 进入项目配置对话框,如下图配置后点击 Finish 完成。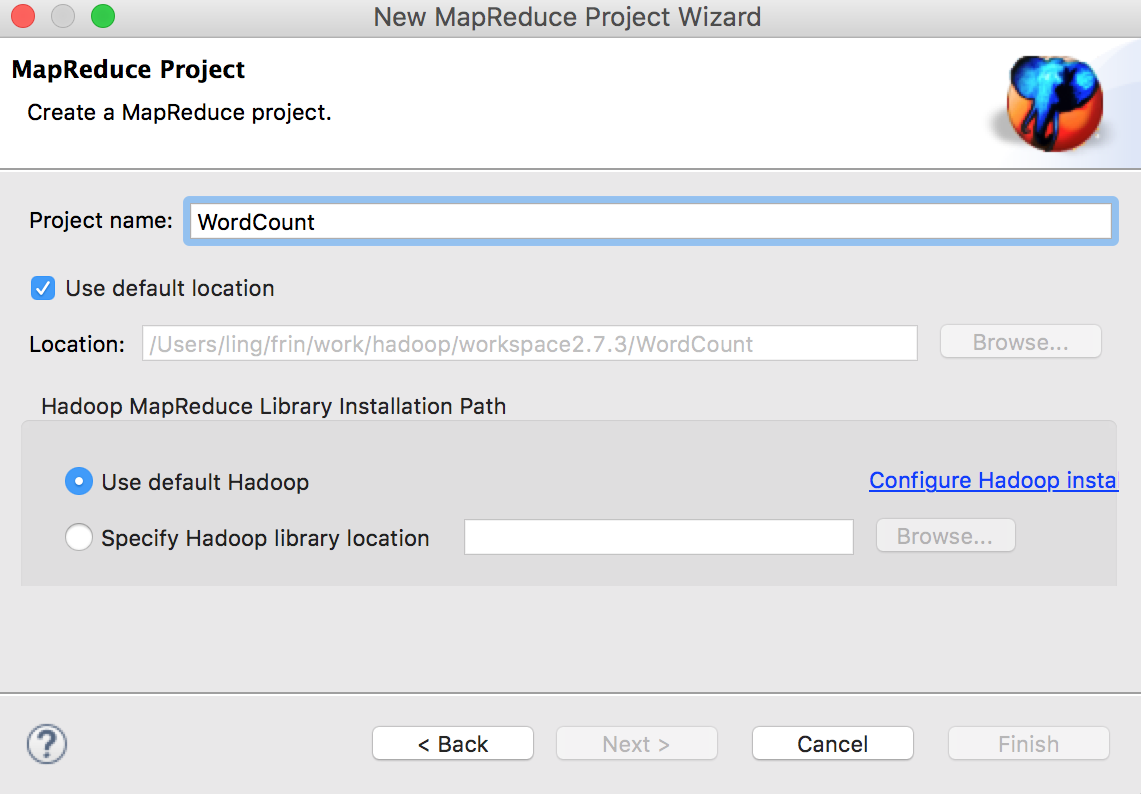
准备 MapReduce 作业
直接将 Hadoop 源代码中的 /hadoop-mapreduce-examples/src/main/java/org/apache/hadoop/examples/WordCount.java 复制到新建的 MapReduce 工程中。
准备数据
在 HDFS 上创建目录 /user/frin/input,并上传 example.txt 文件,内容如下:
hello world
hadoop example
word count
hadoop map reduce
hadoop hdfs
配置输入/输出
在 WordCount.java 代码中点击右键,在弹出的菜单中选中 Run As -> Run Configurations…。在弹出的对话框中双击 Java Application 选项,在 (x)=Arguments 选项卡中配置程序参数,如下图: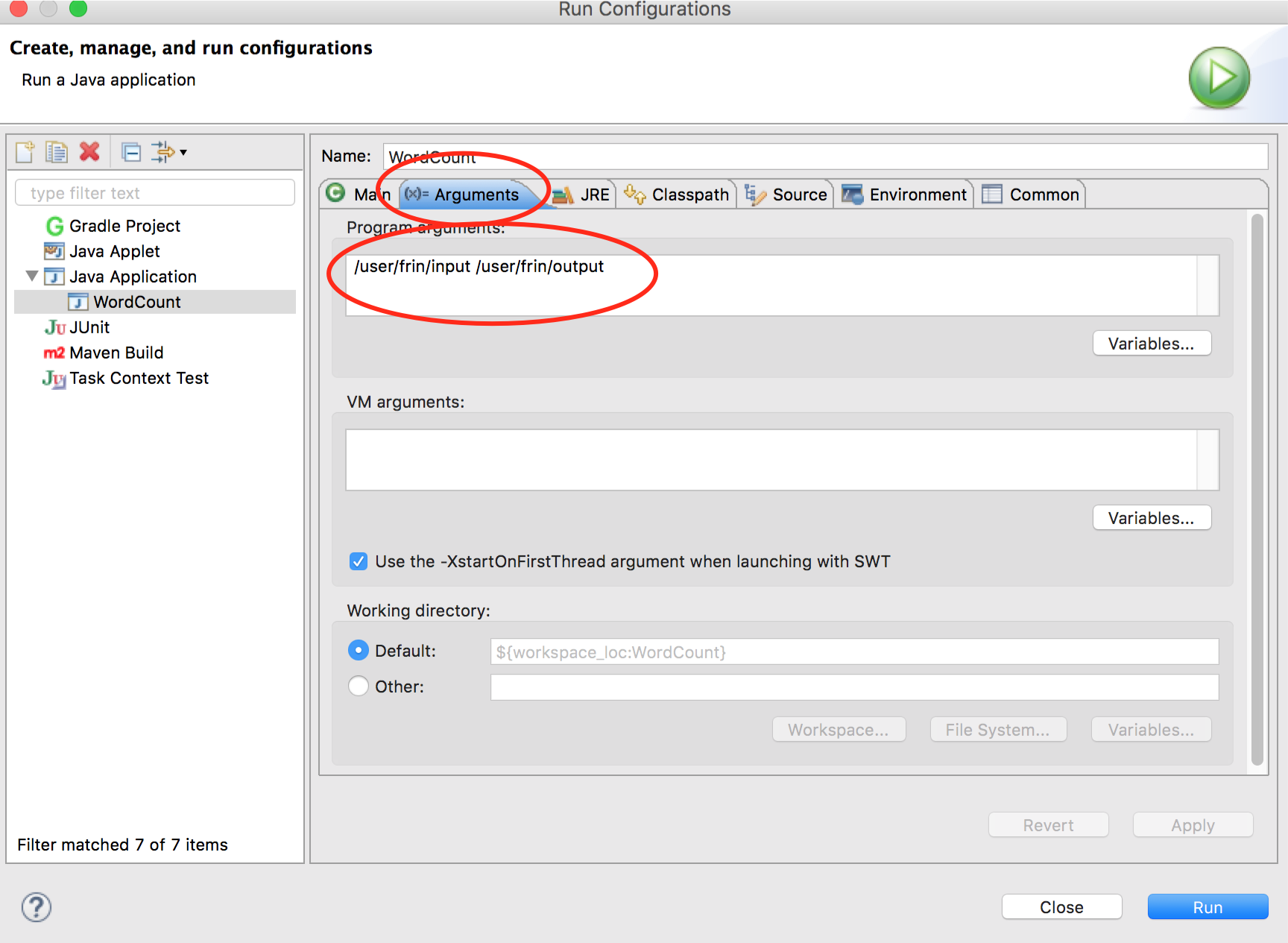
配置后点击 Apply 完成配置。
运行作业
在 WordCount.java 代码中点击右键,在弹出的菜单中选中 Run As -> Run On Hadoop。在 Console 中会打印程序执行信息。最后执行结果如下图: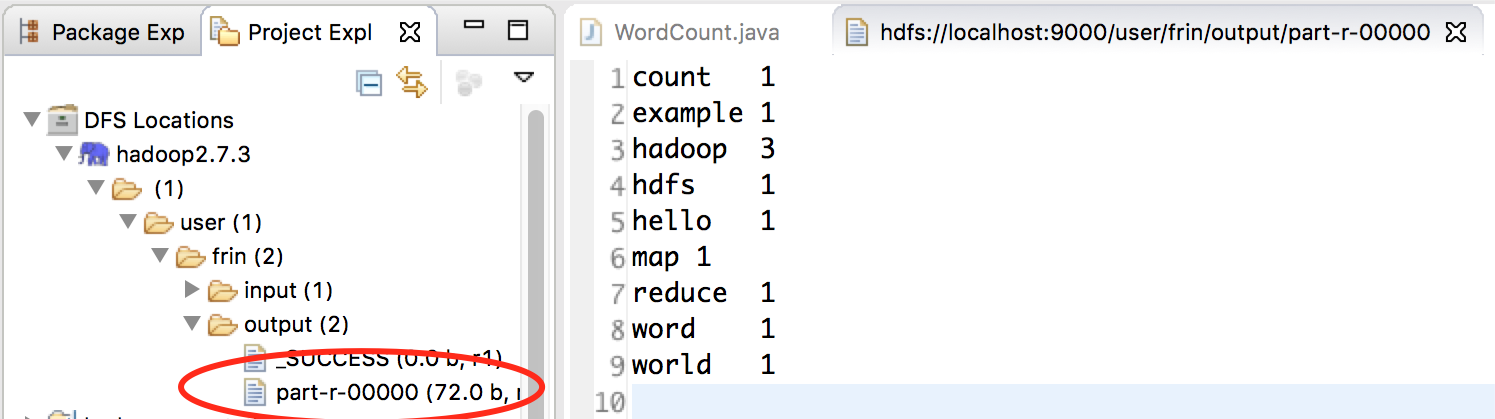
Debug MapReduce 作业
在 WordCount.java 中设置断点,然后点击右键,在弹出的菜单中选择 Debug As -> Debug Configurations… 弹出 Debug 配置窗口,选中 Java Application -> WordCount(WordCount 是刚才配置的运行环境),如下图: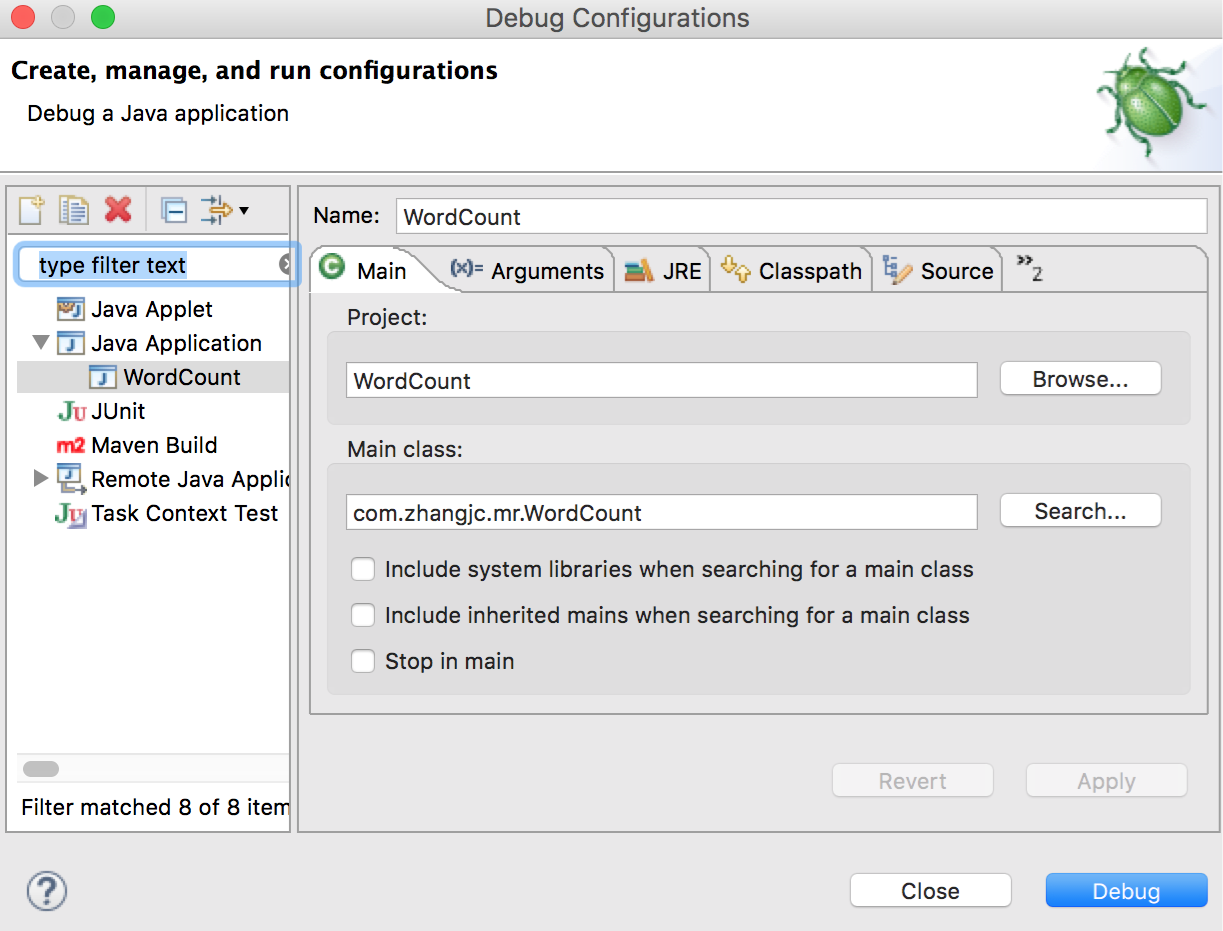
点击 Debug 按钮就可以对 MapReduce 进行调试了,调试界面如下图: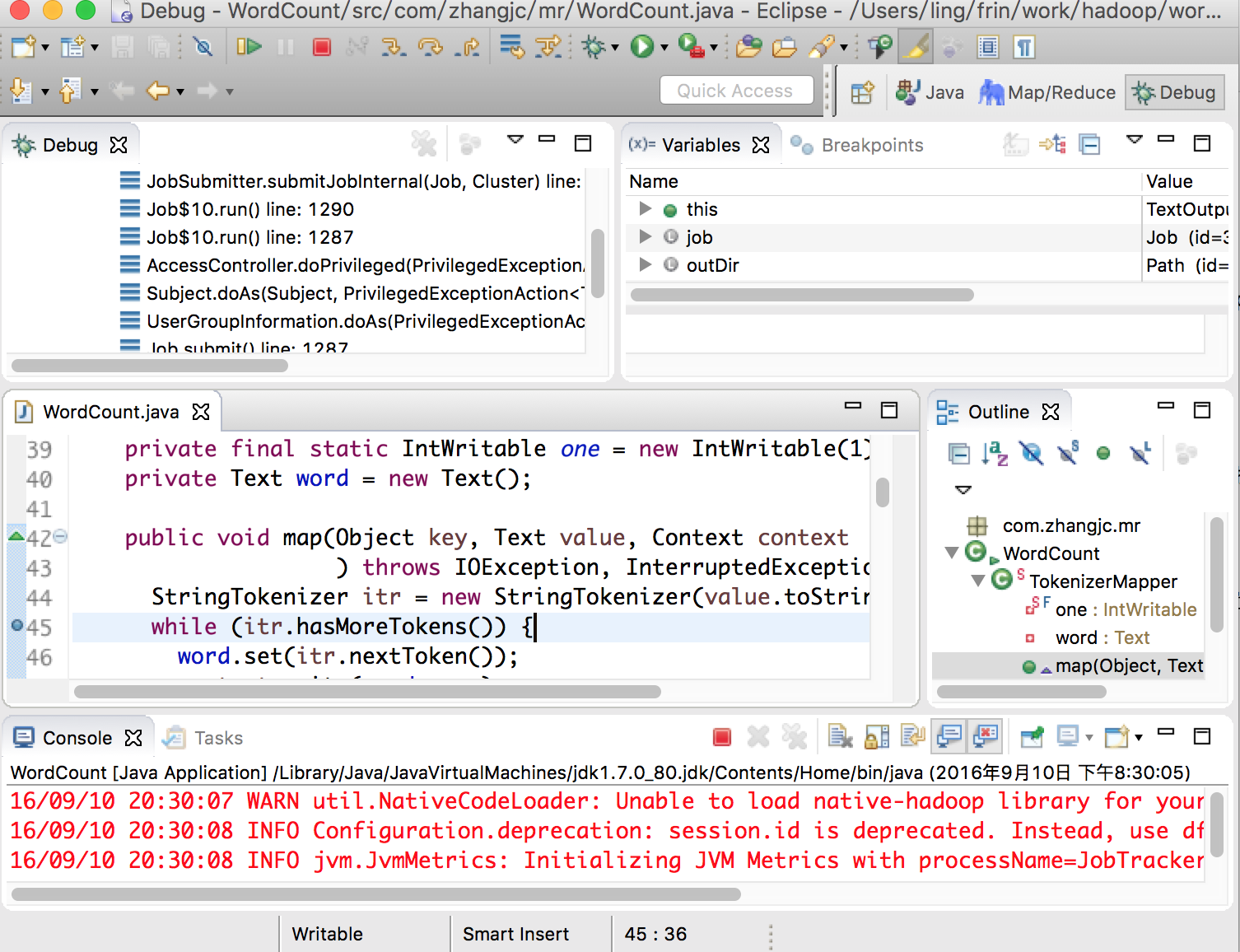
错误
Map/Reduce Locations 错误
Map/Reduce Locations 配置完成后,展开 Location 时会报如下错误,参考了网上的信息也没有解决,但是并不影响 HDFS 管理以及 MapReduce 作业的运行。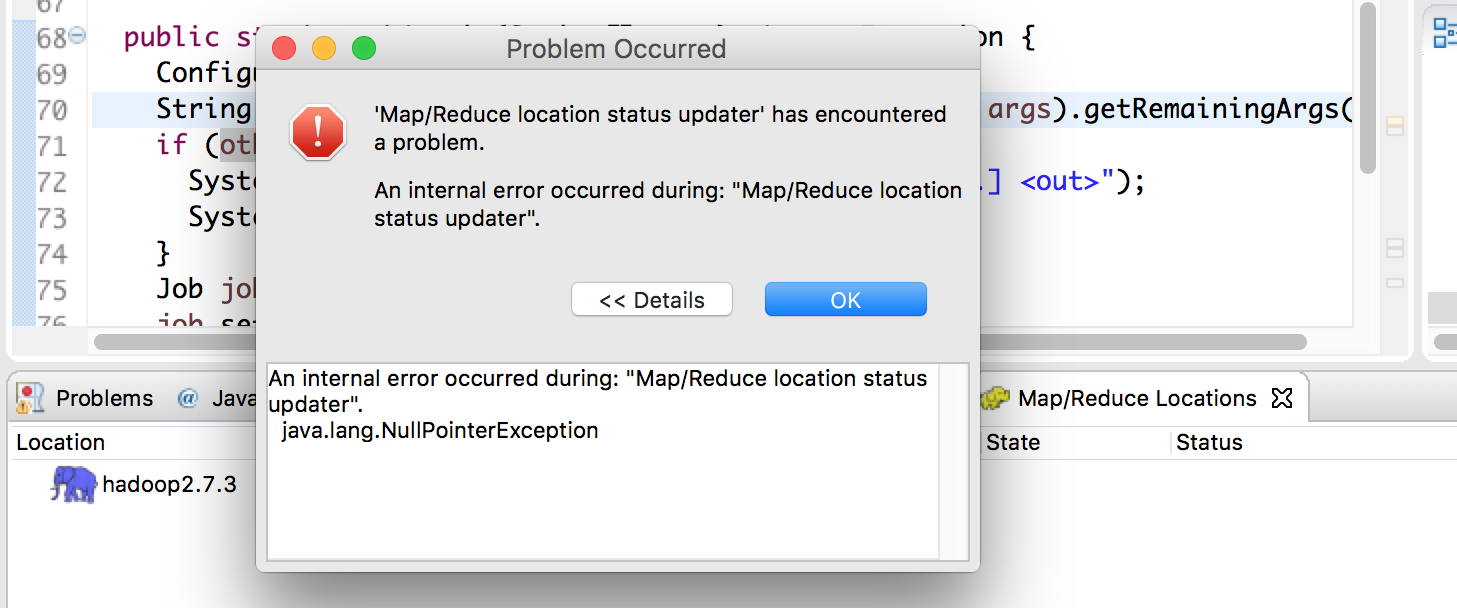
输入路径不存在
报错信息:
Exception in thread "main" org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: file:/user/frin/input
如下图: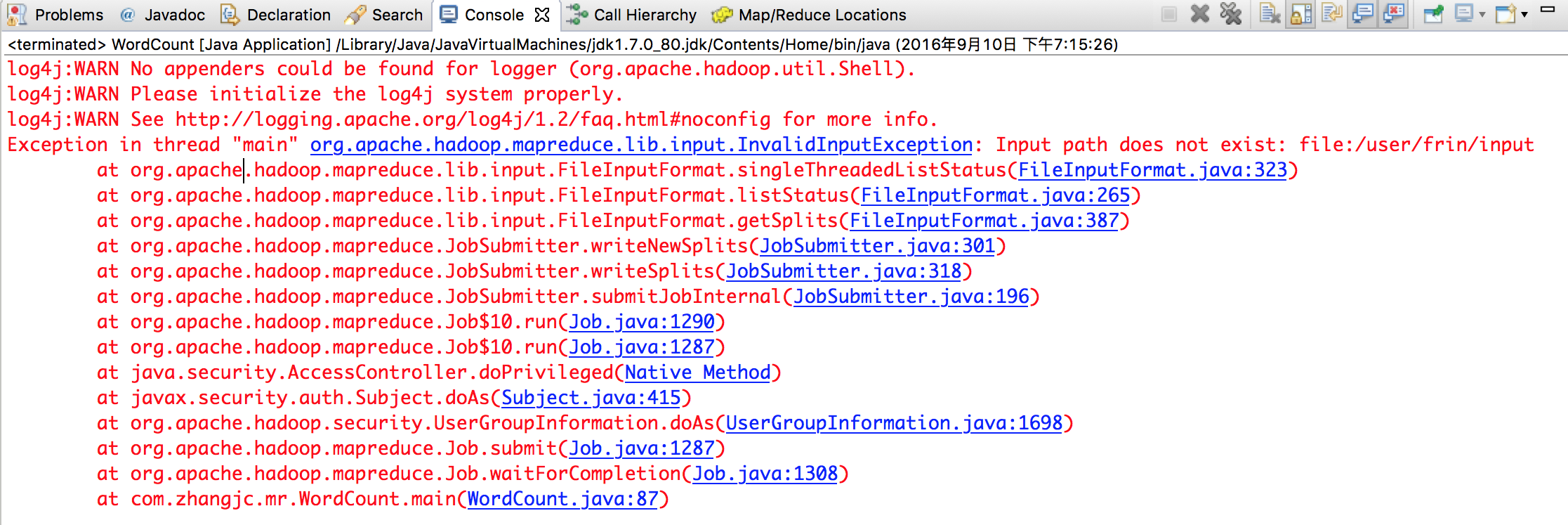
这个错误是因为程序默认从本地磁盘查找路径而非 HDFS,解决方法是将 Hadoop 配置文件目录加入到项目的 CLASSPATH 中。在 WordCount 项目上点击右键,然后选择 Properties。在弹出的对话框中选择 Java Build Path -> Libraries -> Add External Class Folder…,并选择 $HADOOP_HOME/etc/hadoop 目录。配置完成后重新运行作业。