一次DataNode负载严重不均衡问题的排查过程
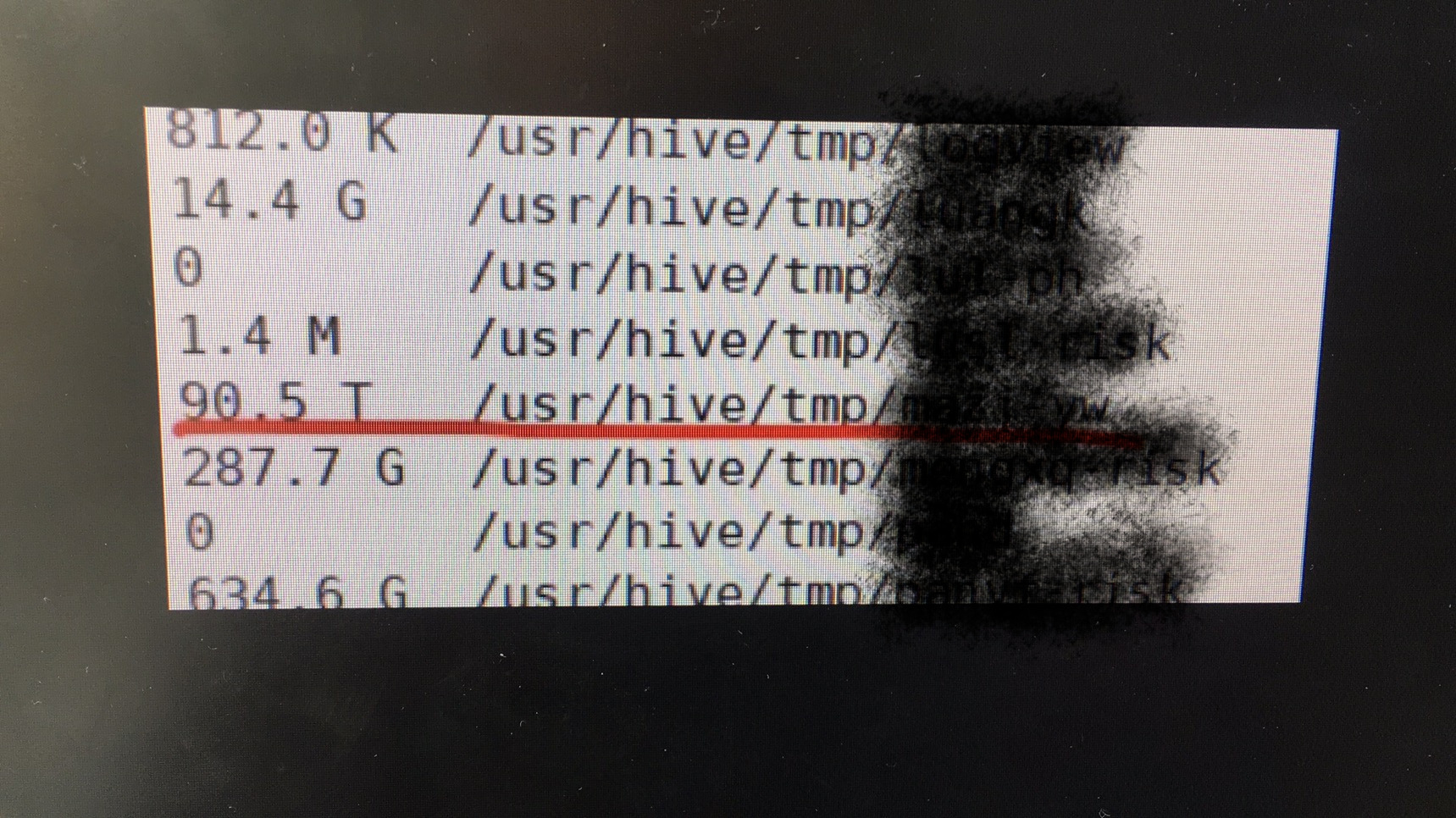
最近两天发现Hadoop集群中的Datanode存储严重不均衡,有一台DN存储增长非常快,远远超出了其他节点。即使启动了Balance进城也无法解决问题。
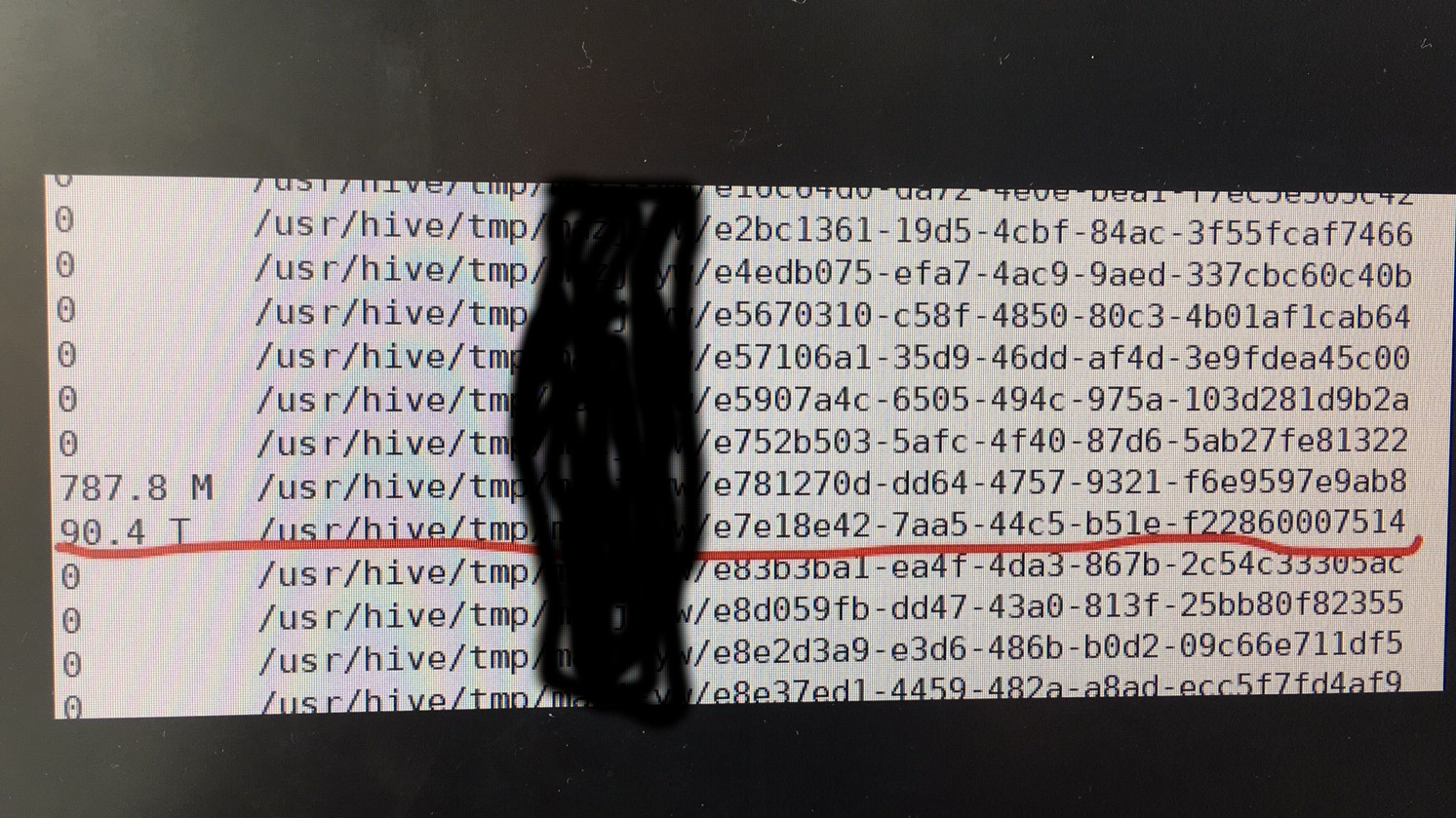
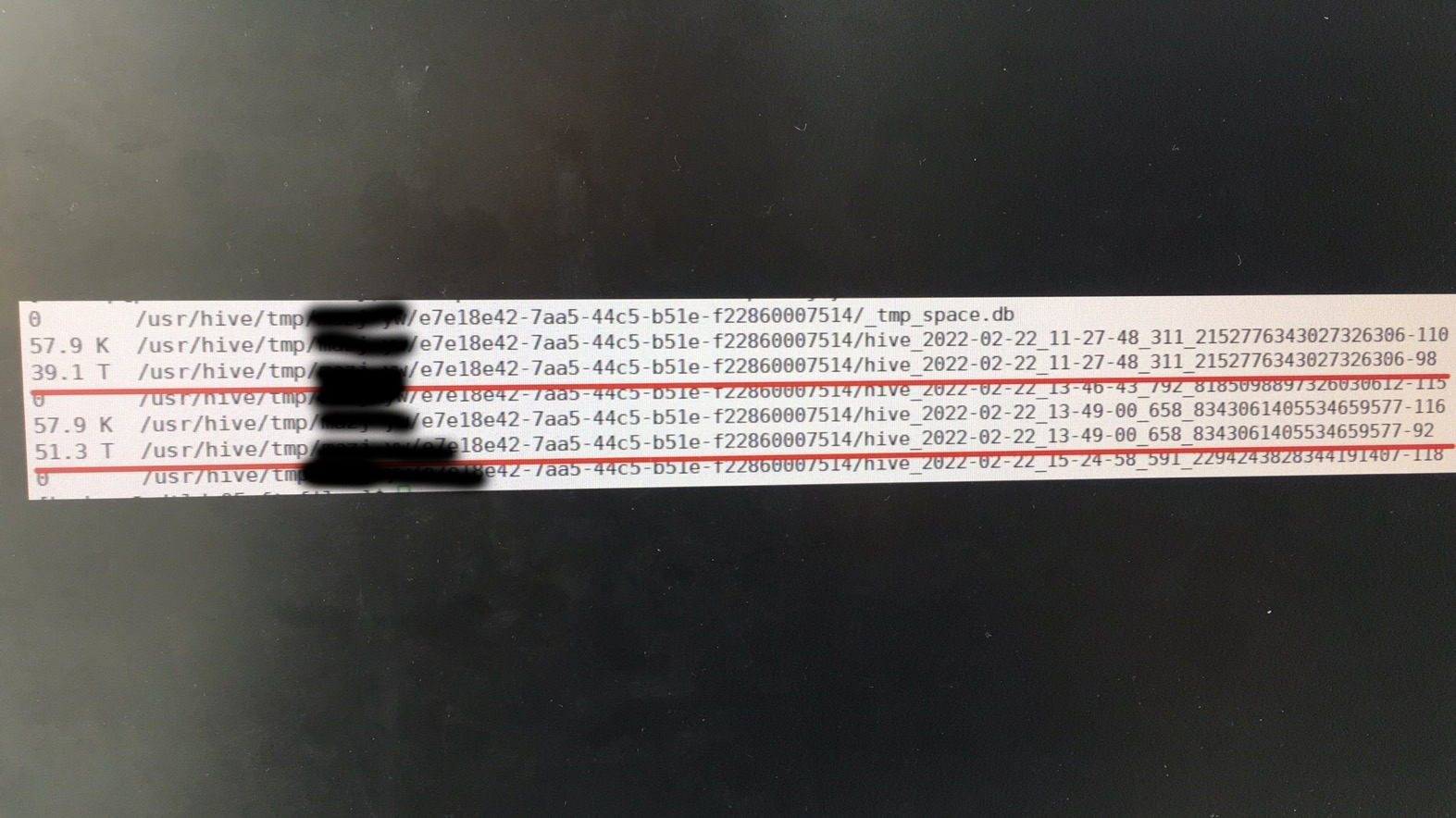
经过排查发现是因一个异常任务停留在reduce阶段,在不停的向HDFS写数据。而这个Reduce Task就是在存储增长非常快的节点上运行的。分析原因是Reduce Task会优先向运行在的节点本地写数据,副本会分布在其他节点上。所以,问题节点增长非常快,而其他节点并看不出明显异常。
以下是排查过程的图片: