Spark宽依赖与窄依赖
Spark的宽依赖与窄依赖是跟数据分区关联的概念。我们知道Spark会将数据集
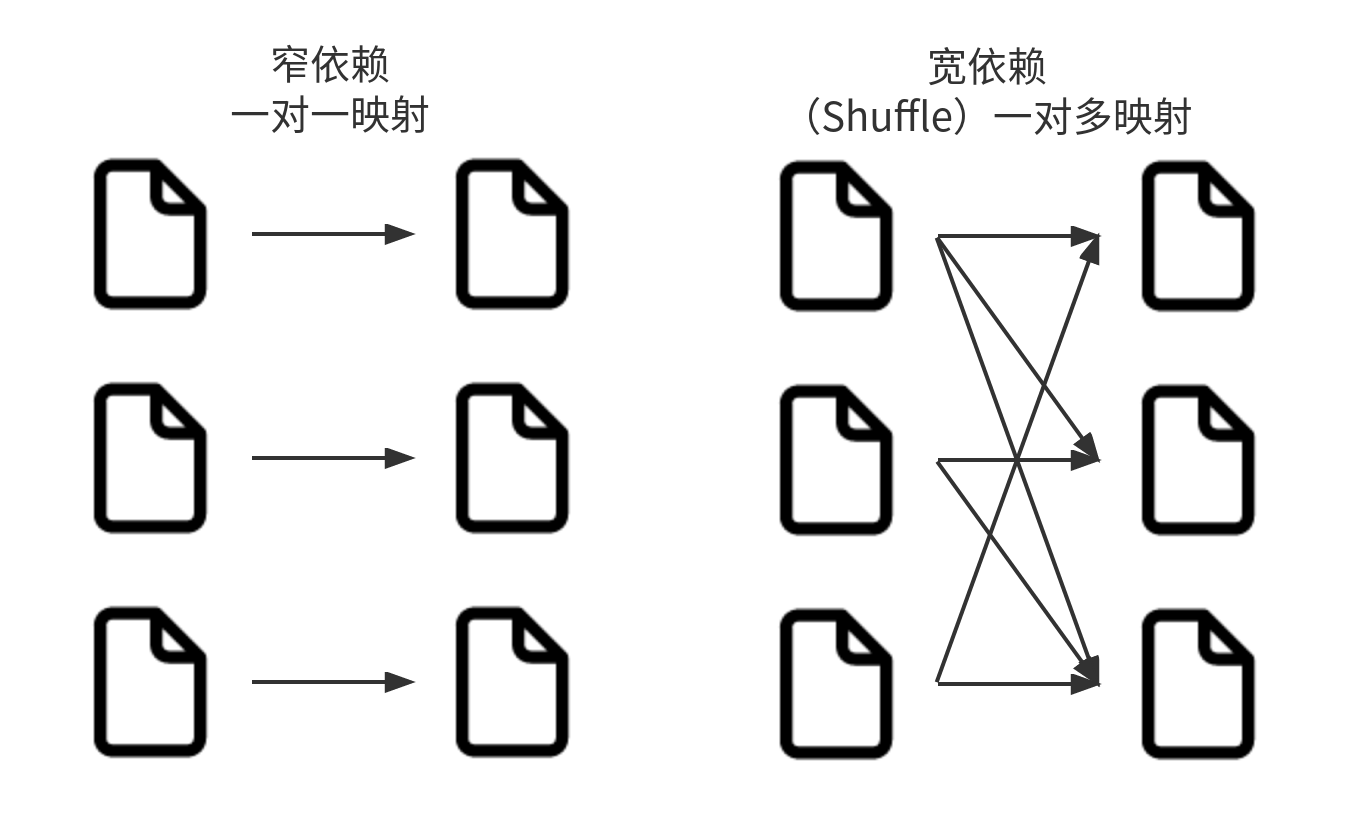
- 窄依赖:每个输入分区仅决定一个输出分区。Spark窄依赖自动执行流水线处理,意味着多个过滤操作全部在内存中执行。
- 宽依赖:每个输入分区决定多个输出分区。具有宽依赖关系的转换就是经常说的洗牌(shuffle)操作。执行shuffle操作时,Spark会将结果写入磁盘。
针对宽依赖的优化是讨论比较多的话题。这也引出了惰性评估的主题。惰性评估的意思就是等到绝对需要时才执行计算。惰性评估的好处是Spark可以优化整个从输入到输出端的数据流。一个很好的例子就是Dataframe的谓词下推。
其实,我们日常工作中会有很多惰性评估的场景,尤其是解决历史存量问题的时候。例如,我们经常会先收集某方面的存量问题,然后整体分析后提供完整的解决方案。这样更有助于从整体统筹考虑,从而提供更更高效、低成本的解决方案。